
jsoup 라이브러리를 사용해서 웹 스크래핑 하는 방법을 정리해 보겠다.
이 라이브러리를 이용하면 html을 GET, POST 방식으로 가져오는 것부터, 파싱 하는 것까지 한 번에 처리할 수 있다.
jsoup document
Jsoup (jsoup Java HTML Parser 1.16.1 API)
public class Jsoup extends Object The core public access point to the jsoup functionality. Author: Jonathan Hedley Method Summary Get safe HTML from untrusted input HTML, by parsing input HTML and filtering it through an allow-list of safe tags and attribu
jsoup.org
1. 스크래핑할 사이트 분석 - Yahoo Finance
Yahoo Finance - Stock Market Live, Quotes, Business & Finance News
At Yahoo Finance, you get free stock quotes, up-to-date news, portfolio management resources, international market data, social interaction and mortgage rates that help you manage your financial life.
finance.yahoo.com
Yahoo Finance 사이트에서 해당 회사에 배당금 내역을 스크래핑해보려고 한다.
데이터를 추출하기 위해서 가장 먼저 해야 될 것은 필요한 데이터가 웹사이트에 어디에 위치하는 지를 알아야 한다.

nike를 검색해 보면, 나이키의 주식 정보를 볼 수 있다.

Historical Data 카테고리에 들어가 보면, 배당금 내역을 조회할 수 있다.
배당금은 최소 달 (month) 단위로 배당되기 때문에, Frequency를 Daily 가 아닌 Monthly로 조회를 해주었고 기간은 Max로 설정하여 모든 배당금 내역을 조회할 수 있도록 설정하였다.
2. robots.txt 확인하기
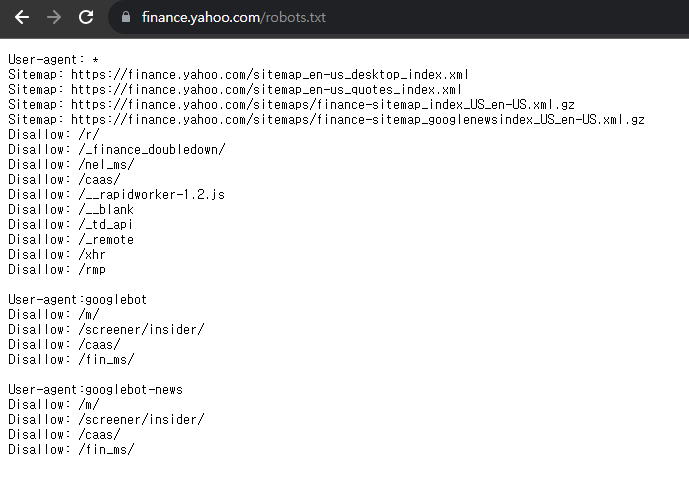
웹 사이트를 스크래핑할 때 중요한 사항은 스크래핑이 허용되는지 확인해야 한다.
robots.txt를 확인하는 방법은 스크래핑할 사이트 뒤에 robots.txt 를 추가하면 된다.
현재 배당금을 가져올 url 은 https://finance.yahoo.com/quote/NKE/history?period1=344563200&period2=1690588800&interval=1mo&filter=history&frequency=1mo&includeAdjustedClose=true 이다. quote라는 경로에 위치해 있는데, robots.txt 파일을 확인해 보면, Disallow에 quote 경로가 해당된 게 없으니 스크래핑을 해도 무관하다.
🚨 하지만, Disallow를 하지 않는다고 해서, 서버에 무리가 갈만한 요청을 보내면 안 된다는 것을 주의해야 한다!
3. 웹 스크래핑 하기
3.1 jsoup 라이브러리 추가하기
implementation group: 'org.jsoup', name: 'jsoup', version: '1.7.2'build.gradle 에 jsoup 의존성을 추가해 준다.
3.2 웹 사이트에 요청 보내기
웹 스크래핑을 하기 전에, 첫 번째로 해야 될 일은 웹 사이트에 요청을 보내서 html을 받아와야 한다.
// url 요청
Connection connection = Jsoup.connect("https://finance.yahoo.com/quote/NKE/history?period1=344563200&period2=1690588800&interval=1mo&filter=history&frequency=1mo&includeAdjustedClose=true");
Document document = connection.get(); // GET 으로 요청하고, 요청 결과를 Document 객체로 반환- Jsoup.connect(String url)
해당 url로 요청하여 Connection 객체를 생성하는 메서드
- connection.get()
url을 GET으로 요청하고, 요청된 결과를 HTML 문서로 파싱 된 형태로 Document 객체로 생성하는 메서드
만약에 POST로 요청을 보내고 싶다면, post()로 요청을 하면 된다.


jsoup document를 참고하면, 다양한 메서드들이 있어서 관련 설명을 보면 이해하기 쉽다!
3.3 HTML 문서 파싱


스크래핑할 데이터가 있는 데이터 영역의 테이블 태그가 data-test = "historical-prices"로 설정되어 있기 때문에 이 속성을 기준으로 Element 들을 가져와야 한다.
Elements elements = document.getElementsByAttributeValue("data-test", "historical-prices");
Element element = elements.get(0);- .getElementsByAttributeValue(String key, String value)
Document는 Element를 상속받은 클래스이기 때문에, 파싱을 하려면 Element 클래스의 관련 메서드들을 확인해야 한다. 이 부분은 jsoup document를 참고하면 알 수 있다.
getElementsByAttributeValue(String key, String value)는 특정 값을 가진 속성이 있는 요소를 찾아서 Element 객체로 반환하는 메서드이다.
Elements elements = document.getElementsByAttributeValue("data-test", "historical-prices");
Element element = elements.get(0);
System.out.println(element);

이 element 값들을 출력해 보면, data-test = "historical-prices" 테이블의 Element를 잘 찾아온 것을 확인할 수 있다. 하지만, 배당금에 대한 정보를 뽑아내기 위해서 정제를 해야 한다.
3.4 데이터 파싱

HTML <table> 태그는 하위 태그들로 <thead>, <tbody>, <tfoot> 을 갖는다.
위에 element 값이 출력된 것을 보면, tbody에 배당금과 주가 관련한 정보들이 있기 때문에, tbody 영역을 추출해야 한다.
(1) tbody 영역 추출
Element tbody = element.children().get(1);element에서 tbody를 추출하기 위해서는 .children().get(1) 을 사용한다.
만약에, thead를 추출하고 싶다면 .children().get(0)
tfoot을 추출하고 싶다면 .children().get(2) 를 사용하면 된다.
(2) for 문을 통해 tbody를 순회하면서, 해당 데이터 가져오기

배당금 데이터는 전부 Dividend로 끝나고 있기 때문에, tbody 안에 있는 데이터를 순회하면서 해당 배당금 데이터만 추출해야 한다.
Element tbody = element.children().get(1);
for (Element e : tbody.children()) {
String txt = e.text(); // 텍스트에만 해당하는 데이터를 String으로 반환
if (!txt.endsWith("Dividend")) {
continue;
}
System.out.println(txt);
}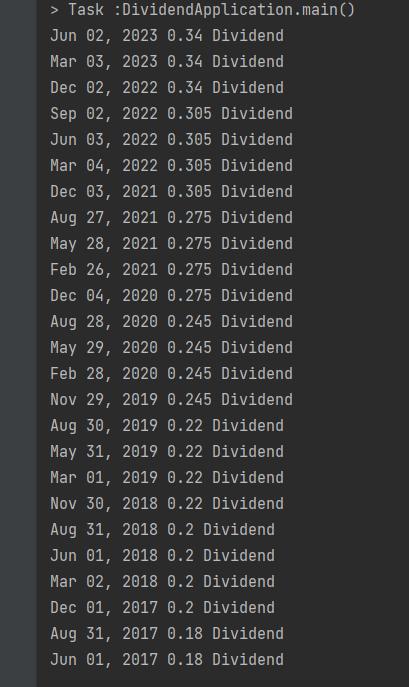
Dividend에 해당하는 데이터가 잘 출력되는 것을 확인할 수 있다.
(3) 원하는 형태로 데이터 파싱하기
배당금 내역을 저장해야 하니까, 이 텍스트를 공백으로 구분해서 연, 월, 일, 배당금 내역을 추출할 것이다.
String[] splits = txt.split(" ");
String month = splits[0];
int day = Integer.parseInt(splits[1].replace(",", ""));
int year = Integer.parseInt(splits[2]);
String dividend = splits[3];
System.out.println(year + "/" + month + "/" + day + " -> " + dividend);
4. 전체 코드
public static void main(String[] args) {
try {
Connection connection = Jsoup.connect("https://finance.yahoo.com/quote/NKE/history?period1=344563200&period2=1690588800&interval=1mo&filter=history&frequency=1mo&includeAdjustedClose=true");
Document document = connection.get();
Elements elements = document.getElementsByAttributeValue("data-test", "historical-prices");
Element element = elements.get(0);
Element tbody = element.children().get(1);
for (Element e : tbody.children()) {
String txt = e.text(); // e.text()
if (!txt.endsWith("Dividend")) {
continue;
}
String[] splits = txt.split(" ");
String month = splits[0];
int day = Integer.parseInt(splits[1].replace(",", ""));
int year = Integer.parseInt(splits[2]);
String dividend = splits[3];
System.out.println(year + "/" + month + "/" + day + " -> " + dividend);
}
} catch (IOException e) {
e.printStackTrace();
}
}